· 4 min read
What Does It Mean to Shift Left in Data?
What is shifting left in Data and how should you go about it.
By: Oxana Urdaneta
What Does It Mean to Shift Left in Data?
Many data organizations are embracing the concept of shifting left, recognizing the need to manage their data earlier in the pipeline and reap the benefits sooner. This approach isn’t just about data quality—it’s about ensuring compliance, security, and other critical practices are integrated into your data processes.
In practical terms, shifting left means moving your data operations—like transformation, processing, and quality checks—closer to where raw data enters the system. Imagine your data flow diagram: raw data sits on the left, and as it moves right, it becomes more refined and business-ready, ultimately reaching BI tools or data science applications. Shifting left is all about tackling key processes earlier in this flow.
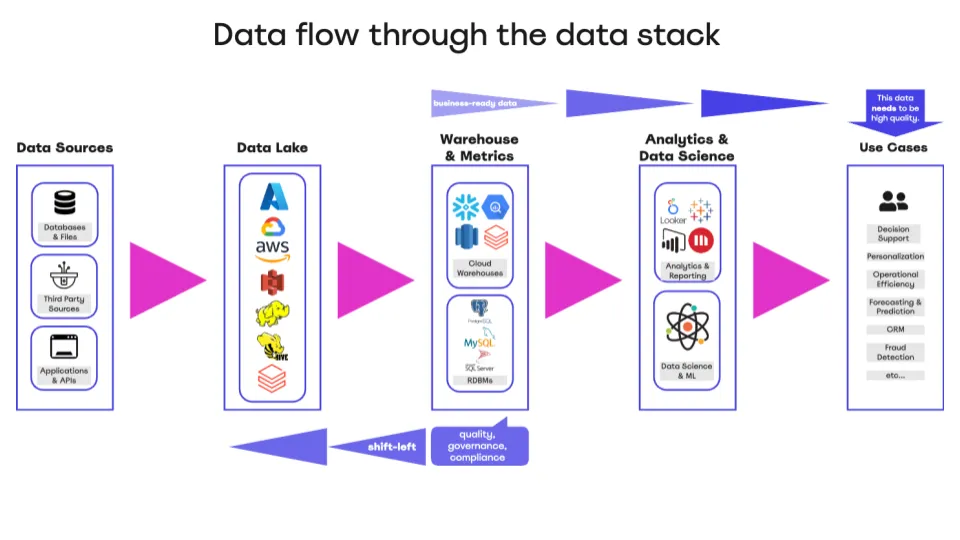
This concept, borrowed from software development (specifically DevOps), emphasizes early testing, quality checks, and performance evaluations. In the same way that Test-Driven Development (TDD) in software ensures quality before code is even written (design your test, then write the code and ensure those tests will pass), shifting left in data ensures that your data is reliable from the start.
Why Do Data Teams Shift Left?
- Proactive Data Quality: By moving data quality checks earlier in the pipeline, you can catch and resolve issues sooner. For instance, if your “customer” table has a 50% null rate in the email column, identifying this early prevents it from contaminating downstream transformations and uses of that data.
- Efficient Governance and Compliance: Addressing governance and compliance requirements earlier in the data lifecycle allows companies to meet these obligations more effectively. For example, if PII is anonymized from the start, there’s less risk and fewer places to manage downstream.
- Cost Savings: Cloud data warehouses like Snowflake or BigQuery can get expensive with heavy transformations. Shifting left means performing more operations and transformations in cost-effective environments like data lakes or raw data layers.
- Faster Time-to-Insight: When data is prepared earlier, it accelerates the delivery of actionable insights, speeding up data science explorations and business decision-making.
The Reality of Shifting Left
While shifting left offers numerous benefits, it’s not a quick change. This process requires significant coordination, collaboration, and time. Migrating workloads, testing to ensure data quality, and ensuring your orchestration is stable and data pipelines are not broken will all take time. Data observability will be crucial throughout this journey to maintaining data reliability, ensuring timely data landing, and preventing pipeline disruptions.
Our Recommendation
Shifting left is a smart strategy, but it’s crucial not to neglect or reduce the monitoring and tracking of data quality and reliability (data observability) at every stage of the pipeline. Early-stage data quality checks are essential but remember: the final mile of data is what the business consumes. There will always be transformations closer to the “right” of your data stack as data is refined for business use cases. Each transformation carries the risk of errors that could compromise data reliability and impact decision-making. In other words, ensure that potential uncaught issues on the right do not diminish the benefits of shifting left.
Data observability should be applied across the whole stack, ensuring you catch issues early and maintain reliability where it matters most—at the point of business decision-making. Shifting left, when combined with robust observability practices, ensures your data is accurate, reliable, cost-effective, and ready for strategic use.
How to do this?
An out-of-the-box data observability solution is a great option if you have the budget and limited time. Such solutions will allow you to focus on migrating your workloads, while the automation will verify the reliability of your data pipelines as they are migrated and alert you of any anomalies detected.
However, if resources are more constrained, you have several approaches to consider. To evaluate these, you must remember that the most critical aspect of shifting left is maintaining the reliability of your data post-migration. Stakeholders won’t accept inconsistent data as a result of your shift-left efforts. Consistency is key here.
You might migrate your data and compare the newly migrated left-side data assets with their right-side counterparts. If you do this, wait until you have verified consistent results on both ends before migrating analytics workloads to rely on the newer (left) data assets.
Alternatively, focus on gradually improving the quality of your right-side data assets, working closely with stakeholders. This incremental approach allows you to refine your data quality practices before fully committing to a shift-left strategy. Once you’ve successfully shifted left, applying the same quality and assurance practices to the left side will become more manageable.
Recommendation: The incremental quality improvement approach is advisable. This allows you to bring stakeholders to the conversation and understand their expectations of the data before attempting to rewrite workloads in a different stack/environment. By aligning with stakeholders’ expectations, your team will better understand the data requirements, which can facilitate a faster and more consistent migration of workloads.