· 7 min read
Data Modeling Essentials - From Normalization to Dimensional Modeling
Learn the essentials of data modeling, from normalization to dimensional modeling, to enhance data integrity and performance.
By: Oxana Urdaneta
Introduction to Data Modeling
Data modeling is both an art and a science, forming the foundation of robust data architectures that support business intelligence, analytics, and decision-making processes. Effective data models define the overall structure and relationships of data, maximizing its usability for various purposes. While methodologies for data modeling have evolved into hybrid versions, the two primary methods—normalization and dimensional modeling—remain widely used. Each method has unique applications and benefits, with the choice between them depending on how data is stored and expected to be used. In this article, we will delve into each approach.
The Normalized Approach (3NF)
Normalization, often called the Third Normal Form (3NF), is a method for organizing data to reduce redundancy and improve data integrity. While earlier forms like 1NF and 2NF exist, 3NF is preferred for its balance of efficiency and comprehensiveness.
In a normalized approach, data is divided into different entities, clearly distinguishing which entity should hold which attribute. This division ensures that data is organized logically and makes it easier to update, retrieve, or delete records when needed. There’s a clear understanding of the relationships between entities and attributes, such as one-to-one, one-to-many, and many-to-many. Typically, the attribute belongs to the same table if the relationship is one-to-one. For example, in a retail data model, entities might include customer, product, store, item, and transaction. Entities are expected to represent the real world as closely as possible. This separation reduces data duplication and maintains data integrity.
Key Concepts of Normalization
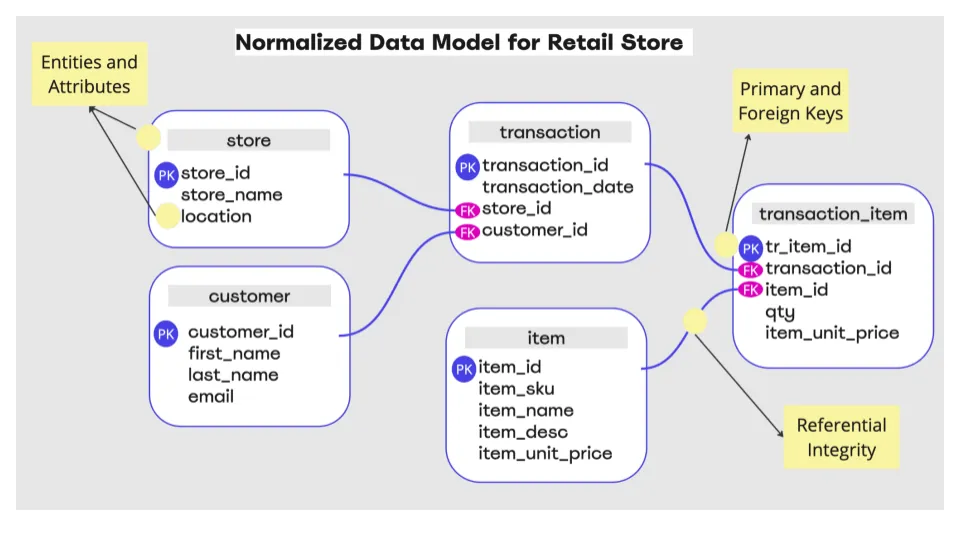
- Entities and Attributes: Data is organized into tables based on entities and their attributes. For instance, customer addresses could be stored in a separate table, customer_address, linked to the customer table via a customer_id.
- Primary and Foreign Keys: Each table has a primary key, and relationships between tables are defined through foreign keys. These keys ensure referential integrity, meaning data referenced in one table must exist in another.
- Referential Integrity: This ensures consistent relationships between tables. For example, you cannot add an item to a shopping cart if the item ID does not exist in the item table.
Use Cases for Normalization
Normalization is ideal for transactional systems, such as point-of-sale (POS) systems, inventory management, and banking systems. These systems benefit from easy row-level updates and maintaining data accuracy through unique primary keys. For example, Amazon’s inventory system requires each item to be accurately inserted, referencing the seller ID and category ID. Updates and deletions affect single rows, but retrieving comprehensive information necessitates multiple joins.
You could still do reporting using a normalized model. However, it would not be ideal because of the number of joins, complexity of queries, performance issues, and the inability to have historical data.
Databases supporting normalization, such as PostgreSQL and SQL Server, handle Online Transactional Processing (OLTP). The keyword here is “Transactions,” as they facilitate transaction-oriented applications. These databases:
- Are optimized for managing and updating individual records efficiently
- Enable a large number of small and simple transactions that involve small amounts of data.
- Ensure data integrity through ACID properties (Atomicity, Consistency, Isolation, Durability), guaranteeing that all transactions are processed reliably.
- Support many users in processing transactions very quickly.
Dimensional Modeling
Dimensional modeling, on the other hand, is designed for analytical purposes. It groups data attributes for aggregation and summary, making it ideal for reporting and data analysis. This method simplifies queries and reduces the need for complex joins, overcoming the limitations of 3NF. Dimensional models are also more scalable for analytics, particularly in systems that require historical analysis and large datasets. The analytical use cases of the data need to be thoroughly understood to model it correctly and group the required attributes together, as data will be pre-aggregated and summarized to enable fast query performance.
To better understand dimensional modeling, let’s dive into the key concepts:
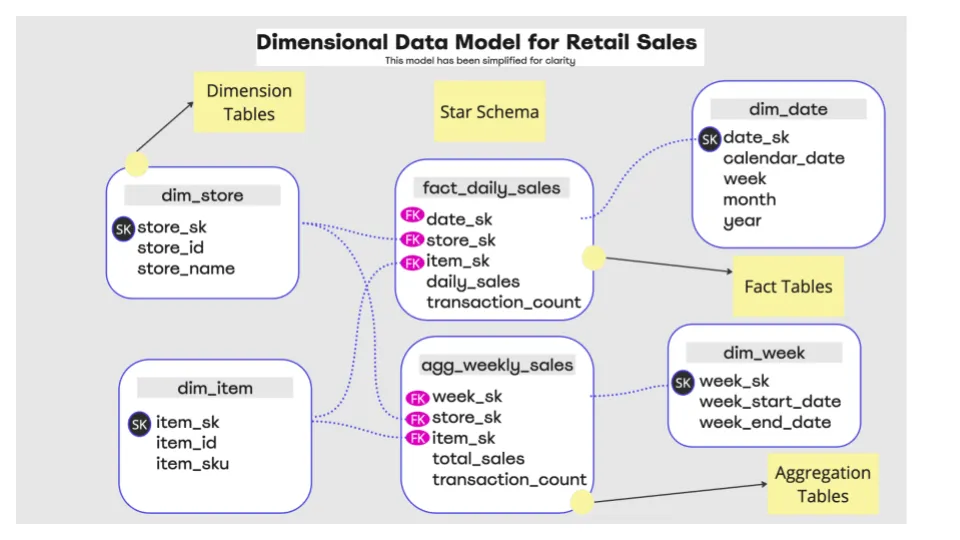
- Star Schema: A common dimensional model features a central fact table surrounded by dimension tables. Fact tables contain measurable, quantitative data, while dimension tables store descriptive attributes. For example, a fact table could be used for daily sales, and dimension tables for store, item, customer, etc.
- Fact and Dimension Tables: Fact tables include foreign keys that link to dimension tables, allowing easy data slicing and filtering based on dimensions. All dimensions need a primary or surrogate key to identify a row uniquely.
Fun fact: Given that joins of integers perform faster than strings, it was an implicit rule always to have numeric primary keys or surrogate keys for all dimensions to speed up queries. So even a dimension like “countries” would have a numeric identifier on top of it. - Aggregation and Summarization: Dimensional models are optimized for quick data aggregation and summarization, essential for business intelligence (BI) and data warehousing.
Use Cases for Dimensional Modeling
Dimensional modeling is best suited for data warehousing, analytical processing, and reporting. For instance, to answer “How many sales were made last month in our Pennsylvania stores?” a dimensional model allows for efficient data retrieval and aggregation. Data is typically inserted in batches and retrieved in summarized forms, optimized for large data volumes. Aggregates at higher granularities, like quarterly sales, enable speedy retrieval and in-depth analysis at various levels of granularity.
Technologies supporting dimensional modeling include big data technologies like Apache Hive and cloud data warehouses such as Snowflake, Amazon Redshift, and Google BigQuery. The keyword here is “speed,” and these systems:
- Store metadata at the table and column level that enables quick retrieval of the data requested.
- They are optimized for read-heavy operations and can handle complex queries involving large volumes of data quickly. They often use distributed processing for parallel execution.
- Leverage columnar storage to read only the necessary columns and reduce the speed of analytical queries.
Traditional RDBMs like SQL Server and Postgres can also do the job for smaller data sizes.
Hybrid Data Modeling: Balancing the Benefits
Data architectures often incorporate normalized and dimensional models, leveraging their strengths. Normalized data often feeds dimensional models as the data is prepared for analytics and reporting. The right balance between normalization and dimensional modeling depends on the different use cases, such as the nature of the data, the frequency of updates, and the need for fast retrieval of analytical insights. For instance, a transactional system may store data in a normalized format, while a data warehouse uses a dimensional model for analysis and reporting.
In terms of technologies, data modeling is about how you structure, store, and retrieve (or use) the data. A database is simply a technology for storing data. Still, the choice of which technology to use depends on finding the most efficient solution based on the speed required, the data volume, and the data’s complexity.
Ensuring Data Quality Across Models
Maintaining high data quality is essential, regardless of the modeling approach. While 3NF provides strict constraints for data integrity, dimensional models require careful design to ensure data consistency and reliability.
Implementing data observability practices helps continuously monitor and ensure data quality across normalized and dimensional models. This includes automated checks, anomaly detection, and continuous monitoring, ensuring data quality evolves alongside the data. This will enable your data models to grow and evolve over time while ensuring data reliability.
Conclusion
Choosing the right data modeling technique is critical to maximizing the value of your data. A well-modeled data system is essential for business success. Normalization and dimensional modeling offer distinct advantages and are suited to different data systems. By understanding and applying these methods appropriately, you can ensure data integrity, optimize performance, and enable robust analytics.
The key to successful data modeling is in the initial design and maintaining and monitoring of data quality throughout its lifecycle, whether managing transactions or analyzing large datasets.